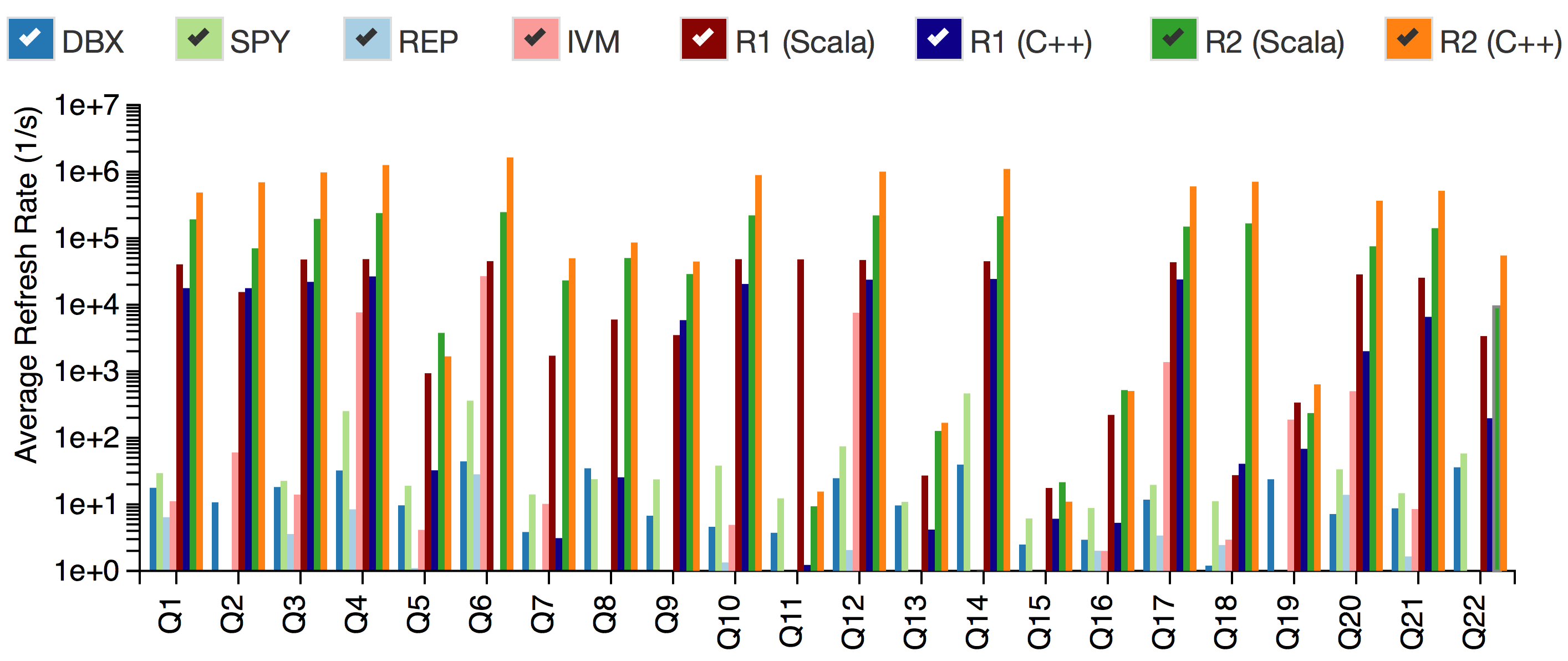
If you cannot see the above graphs, please click here. The underlying performance measurement data can be downloaded from here.
The above graphs show a performance comparison of DBToaster-generated query engines against a commercial database system (DBX), a commercial stream processor (SPY), and several naive query evaluation strategies implemented in DBToaster that do not involve the Higher-Order incremental view maintenance. (The commercial systems remain anonymous in accordance with the terms of their licensing agreements).
In addition, the performance comparison covers generated C++ and Scala programs from both Release 1 (R1) and Release 2 (the current release - R2) releases, in order to compare the performance improvements gained in the latest release.
Performance is measured in terms of the rate at which each system can produce up-to-date (fresh) views of the query results. As you can see, DBToaster regularly outperforms the commercial systems by 3-6 orders of magnitude.
The graphs show the performance of each system on a set of realtime data-warehousing queries based on the TPC-H query benchmark. These queries are all included as examples in the DBToaster distribution.
REP (Depth-0) represents a naive query evaluation strategy where each refresh requires a full re-evaluation of the entire query. IVM (Depth-1) is a well known technique called Incremental View Maintenance (we discuss the distinctions in depth in our technical report). Both of these (REP and IVM) were implemented by a DBToaster-generated engine.
The experiments are performed on a single-socket Intel Xeon E5- 2620 (6 physical cores), 128GB of RAM, RHEL 6, and Open-JDK 1.6.0 28. Hyper-threading, turbo-boost, and frequency scaling are disabled to achieve more stable results.
We used LMS 0.3, running with Scala 2.10 on the Hotspot 64-bit server VM having 14 GB of heap memory, and the generated code was compiled with the -optimise option of the Scala compiler.
A stream synthesized from a scaling factor 0.1 database (100MB) is used for performing the experiments (with an upper limit of 2 hours), while our scaling experiments extend these results up to a scaling factor of 10 (10 GB).